Chapter 6 final parts. Foreign, check and null constraints
Foreign keys
A foreign key is a constraint enforced using the values another table’s field. The classical example is the tables storing the addresses and cities. We can store the addresses with the city field, inline.

Being the city a duplicated value over many addresses, this will cause the table bloat by storing long strings, duplicated many and many times, alongside with the the address. Defining a table with the cities and referencing the city id in the addresses table will result in a smaller row size.

When dealing with referencing data, the main concern is the data consistency between the tables. In our example, putting an invalid identifier for the city in the t_addresses table will result missing data when joining. The same result will happen if for any reason the city identifier in the t_cities table is updated.
The foreign keys are designed to enforce the referential integrity. In our example will we’ll enforce a strong relationship between the tables.

The key is enforced in two ways. When a row with an invalid i_id_city hits the table t_addresses the key is violated and the transaction aborts. Deleting a city from the t_cities table which id is referenced in the t_addresses, will violate the key. The same will updating a i_id_city referenced in the t_addresses.
The enforcement is performed via triggers. The pg_dump or pg_restore option -disable-trigger will permit the the data restore with the schema already in place. For more informations take a look to 9 and 10.
The FOREIGN KEYS have been enriched with an handful of options which
make them very flexible. The referenced table can drive actions on the
referencing using the two options ON DELETE and ON UPDATE. By default
the behaviour is to take NO ACTION if there are referencing rows until
the end of the transaction. This is useful if the key check should be
deferred to the end of the transaction. The other two actions are the
RESTRICT which does not allow the deferring and the CASCADE which
cascade the action to the referred rows.
If we want our foreign key restrict the delete with no deferring and
cascade any update, here’s the DDL.

Another very useful clause available with the foreign and check constraints is the NOT VALID. When the constraint is created with NOT VALID, the initial check is skipped making the constraint creation instantaneous. This is acceptable if the actual data is consistent. The constraint is then enforced for all the new data. The invalid constraint can be validated later with the command VALIDATE CONSTRAINT.
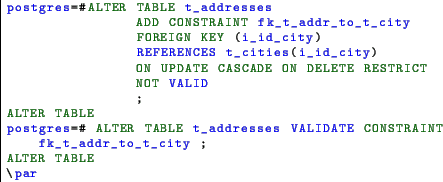
Check constraints
A check constraint is a user defined check to enforce specific condtions on the rows. The definition can be a condition or a used defined function. In this case the function must return a boolean value. As for the foreign keys, the check accepts the NOT VALID clause to speed up the creation.
The check is satisfied if the condition returns true or NULL. This behaviour can produce unpredictable results if not fully understood. An example will help to clarify. Let’s create a CHECK constraint on the v_address table for enforcing a the presence of a value. Even with the check in place the insert without the address completes successfully.
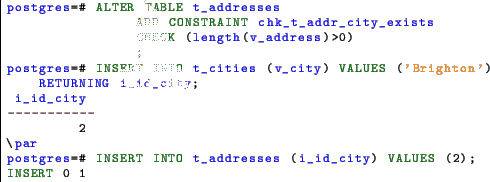
This is possible because the v_address does not have a default value and accepts the NULL values. The check constraint is violated if, for example we’ll try to update the v_address with the empty string.
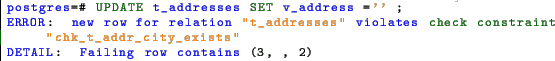
Our check constraint will work as expected if we set for the v_address field a fallback default value.

Please note the existing rows are not affected by the default value
change.
The message for the update and the insert is exactly the same because
PostgreSQL attempts to create a new row in both cases. When the
constraint fails the transaction is rolled back leaving the dead row in
place. We’ll take a better look to the MVCC in 7.6.
Not null
For people approaching the database universe the NULL value can be quite
confusing. A NULL value is an empty object without any type or meaning.
Actually when a field is NULL it doesn’t consumes physical space. By
default when defining a field this is NULLable. Those fields are quite
useful to omit some columns, for example, at insert time.
The NULLable fields can be enforced with an unique constraint as the
NULL are not considered as duplicates. When dealing with the NULL it’s
important to remind the NULL acts like the mathematical zero. When
evaluating an expression with a NULL, the entire expression becomes
NULL.
The NOT NULL is a column constraint which forbids the presence of NULL
in the affected field. Combining a NOT NULL with a unique constraint is
exactly like having enforced a PRIMARY KEY. When altering a field the
table is scanned for validation and the constraint’s creation is aborted
if any NULL value is present on the affected field.
For example, if we want to add the NOT NULL constraint to the field v_address in the t_addresses table the command is just.

In this case the alter fails because the column v_address contains NULL values from the example seen in 6.4. The fix can be performed in a single query using the coalesce function. This function returns the first not null value from the left. This way is possible to change the v_address on the fly to a fixed placeholder .
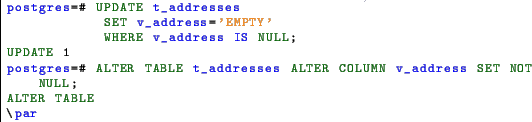
Adding new columns with NULL is quick. PostgreSQL simply adds the new attribute in the system catalogue and manages the new tuple structure considering the new field as empty space. Adding a field with NOT NULL requires the presence of the DEFAULT value as well. This is an operation to consider carefully when dealing with big amount of data. This way the table will be locked in exclusive mode and a complete relation’s rewrite will happen. A far better way is to add a NOT NULL field is to add at first as NULLable field. A second alter will add the default value to have the new rows correctly set. An update will then fix the NULL values without locking the table. Finally the NOT NULL could be enforced without hassle.